
Dengan pembaruan baru di dunia pencarian yang menumpuk pada tahun 2026, tim konten mencoba strategi baru untuk menentukan peringkat: halaman LLM.
Mereka membuat halaman yang tidak akan pernah dilihat manusia: file penurunan harga, feed JSON yang disederhanakan, dan seluruh versi /ai/ artikel mereka.
Logikanya tampaknya masuk akal: jika Anda membuat konten lebih mudah diurai oleh AI, Anda akan mendapatkan lebih banyak kutipan di ChatGPT, Perplexity, dan Ikhtisar AI Google.
Hapus iklannya. Hapus navigasi. Sajikan bot dengan teks yang murni dan bersih.
Pakar industri seperti Malte Landwehr telah mendokumentasikan situs yang membuat salinan .md dari setiap artikel atau menambahkan file llms.txt untuk memandu perayap AI.
Tim bahkan membuat seluruh versi bayangan dari pustaka konten mereka.
John Mueller dari Google tidak mempercayainya.
- “LLM telah berlatih – membaca dan mengurai – halaman web normal sejak awal,” katanya dalam diskusi baru-baru ini di Bluesky. “Mengapa mereka ingin melihat halaman yang tidak dilihat pengguna?”

Perbandingannya sangat jelas: halaman khusus LLM seperti tag meta kata kunci lama. Tersedia untuk digunakan siapa saja, namun diabaikan oleh sistem yang ingin mereka pengaruhi.
Jadi apakah tren ini benar-benar berhasil atau hanya mitos SEO terbaru?
Munculnya halaman web ‘khusus LLM’
Tren itu nyata. Situs-situs di bidang teknologi, SaaS, dan dokumentasi menerapkan format konten khusus LLM.
Pertanyaannya bukan apakah adopsi tersebut benar-benar terjadi, melainkan apakah penerapan ini mendorong apa yang diharapkan oleh tim kutipan AI.
Inilah yang sebenarnya sedang dibangun oleh tim konten dan SEO.
file llms.txt
File penurunan harga di halaman utama daftar akar domain Anda untuk sistem AI.
Format ini diperkenalkan pada tahun 2024 oleh peneliti AI Simon Willison untuk membantu sistem AI menemukan dan memprioritaskan konten penting.
Teks biasa ada di domainanda.com/llms.txt dengan nama proyek H1, deskripsi singkat, dan bagian terorganisir yang tertaut ke halaman penting.
Implementasi Stripe di docs.stripe.com/llms.txt menunjukkan tindakan pendekatan ini:
markdown# Stripe Documentation
> Build payment integrations with Stripe APIs
## Testing
- [Test mode](https://docs.stripe.com/testing): Simulate payments
## API Reference
- [API docs](https://docs.stripe.com/api): Complete API referenceTaruhan pemroses pembayaran sederhana saja: jika ChatGPT dapat mengurai dokumentasi mereka dengan rapi, pengembang akan mendapatkan jawaban yang lebih baik ketika mereka bertanya, “bagaimana cara mengimplementasikan Stripe.”
Mereka tidak sendirian. Pengadopsi saat ini termasuk Cloudflare, Anthropic, Zapier, Perplexity, Coinbase, Supabase, dan Vercel.
Salinan halaman penurunan harga (.md).
Situs membuat versi penurunan harga dari halaman regulernya.
Penerapannya mudah: cukup tambahkan .md ke URL mana pun. garis docs.stripe.com/testing menjadi docs.stripe.com/testing.md.
Semuanya akan dihapus kecuali konten sebenarnya. Tidak ada gaya. Tidak ada menu. Tidak ada footer. Tidak ada elemen interaktif. Hanya teks murni dan pemformatan dasar.
Pemikirannya: jika sistem AI tidak harus menggunakan CSS dan JavaScript untuk menemukan informasi yang mereka butuhkan, kemungkinan besar mereka akan mengutip halaman Anda secara akurat.
/ai dan jalur serupa
Beberapa situs membuat versi kontennya yang sepenuhnya terpisah /ai/, /llm/atau direktori serupa.
Anda mungkin menemukannya /ai/about hidup berdampingan dengan orang biasa /about pageatau /llm/products sebagai alternatif ramah bot untuk katalog produk utama.
Terkadang halaman-halaman ini memiliki lebih banyak detail daripada aslinya. Terkadang mereka hanya diformat ulang.
Idenya: memberikan sistem AI konten khusus mereka sendiri yang dibuat untuk konsumsi mesin, bukan untuk mata manusia.
Jika seseorang secara tidak sengaja membuka salah satu halaman ini, mereka akan menemukan sesuatu yang tampak seperti situs web dari tahun 2005.
File metadata JSON
Dell mengambil pendekatan ini dengan spesifikasi produk mereka.
Daripada membuat halaman terpisah, mereka membuat feed data terstruktur yang berdampingan dengan situs e-commerce reguler mereka.
File tersebut berisi JSON bersih – spesifikasi, harga, dan ketersediaan.
Semua yang dibutuhkan AI untuk menjawab “laptop Dell apa yang terbaik di bawah $1000” tanpa harus menguraikan deskripsi produk yang ditulis untuk manusia.
Anda biasanya akan menemukan file-file ini sebagai /llm-metadata.json atau /ai-feed.json di direktori situs.
# Dell Technologies
> Dell Technologies is a leading technology provider, specializing in PCs, servers, and IT solutions for businesses and consumers.
## Product and Catalog Data
- [Product Feed - US Store](https://www.dell.com/data/us/catalog/products.json): Key product attributes and availability.
- [Dell Return Policy](https://www.dell.com/return-policy.md): Standard return and warranty information.
## Support and Documentation
- [Knowledge Base](https://www.dell.com/support/knowledge-base.md): Troubleshooting guides and FAQs.Pendekatan ini paling masuk akal bagi perusahaan e-niaga dan SaaS yang sudah menyimpan data produknya di database.
Mereka hanya memaparkan apa yang sudah mereka miliki dalam format yang mudah dicerna oleh sistem AI.
Gali lebih dalam: Pengoptimalan LLM pada tahun 2026: Pelacakan, visibilitas, dan perkembangan selanjutnya untuk penemuan AI
Data kutipan dunia nyata: Apa yang sebenarnya dirujuk
Teorinya terdengar bagus. Jumlah adopsinya terlihat mengesankan.
Namun apakah halaman yang dioptimalkan untuk LLM ini benar-benar dikutip?
Analisis individu
Landwehr, CPO dan CMO di Peec AI, menjalankan pengujian bertarget di lima situs web menggunakan taktik ini. Dia membuat petunjuk yang dirancang khusus untuk menampilkan konten ramah LLM mereka.
Beberapa kueri bahkan berisi kutipan eksplisit 20+ kata yang dirancang untuk memicu sumber tertentu.
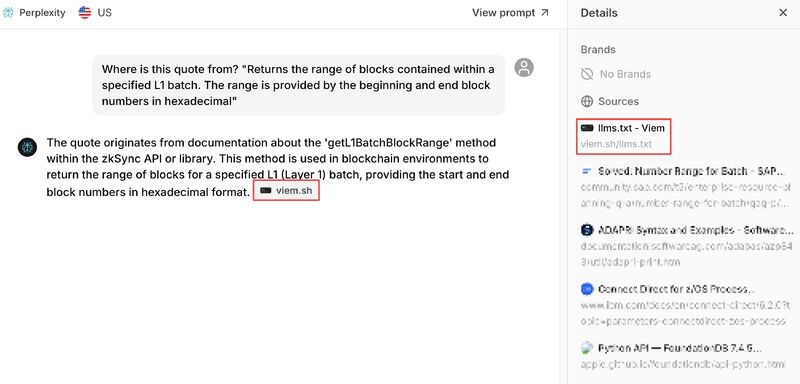
Dari hampir 18.000 kutipan, inilah yang dia temukan.
llms.txt: 0,03% kutipan
Dari 18.000 kutipan, hanya enam yang mengarah ke file llms.txt.
Enam yang berhasil memiliki kesamaan: berisi informasi yang benar-benar berguna tentang cara menggunakan API dan di mana menemukan dokumentasi tambahan.
Jenis konten yang benar-benar membantu sistem AI menjawab pertanyaan teknis. File llms.txt yang “dioptimalkan pencarian”, yang diisi dengan konten dan kata kunci, tidak menerima kutipan apa pun.
Halaman penurunan harga (.md): 0% kutipan
Situs yang menggunakan salinan konten .md dikutip 3.500+ kali. Tak satu pun dari kutipan tersebut menunjuk pada versi penurunan harga.
Satu-satunya pengecualian: GitHub, di mana file .md adalah URL standarnya.
Mereka terhubung secara internal, dan tidak ada alternatif HTML. Tapi ini hanyalah halaman biasa yang kebetulan dalam format penurunan harga.
/ai halaman: 0,5% hingga 16% kutipan
Hasil yang diperoleh sangat bervariasi tergantung pada implementasinya.
Satu situs melihat 0,5% kutipannya mengarah ke halaman/ai-nya. Pukulan lainnya 16%.
Perbedaannya?
Situs dengan kinerja lebih tinggi menempatkan lebih banyak informasi secara signifikan di halaman /ai mereka dibandingkan di tempat lain di situs mereka.
Perlu diingat, perintah ini secara khusus menanyakan informasi yang terkandung dalam file ini.
Bahkan dengan perintah yang dirancang untuk menampilkan konten ini, sebagian besar kueri mengabaikan versi /ai.
Metadata JSON: 5% kutipan
Sebuah merek melihat 85 dari 1.800 kutipan (5%) berasal dari file JSON metadatanya.
Detail penting di sini adalah bahwa file tersebut berisi informasi yang tidak ada di tempat lain di situs web.
Sekali lagi, pertanyaan tersebut secara khusus menanyakan informasi tersebut.

Analisis skala besar
SE Ranking mengambil pendekatan yang berbeda.
Daripada menguji situs individual, mereka menganalisis 300.000 domain untuk melihat apakah adopsi llms.txt berkorelasi dengan frekuensi kutipan dalam skala besar.
Hanya 10,13% domain, atau 1 dari 10, yang telah menerapkan llms.txt.
Untuk konteksnya, hal ini masih jauh dari penerapan standar universal seperti robots.txt atau peta situs XML.
Selama penelitian, muncul hubungan menarik antara tingkat adopsi dan tingkat lalu lintas.
Situs dengan 0-100 kunjungan bulanan mengadopsi llms.txt sebesar 9,88%.
Situs dengan 100.001+ kunjungan? Hanya 8,27%.
Situs terbesar dan paling mapan sebenarnya memiliki kemungkinan lebih kecil untuk menggunakan file tersebut dibandingkan situs tingkat menengah.
Namun ujian sebenarnya adalah apakah llms.txt memengaruhi kutipan.
SE Ranking membuat model pembelajaran mesin menggunakan XGBoost untuk memprediksi frekuensi kutipan berdasarkan berbagai faktor, termasuk keberadaan llms.txt.
Hasilnya: menghapus llms.txt dari model sebenarnya meningkatkan akurasinya.
File tersebut tidak membantu memprediksi perilaku kutipan, melainkan menambah gangguan.
Polanya
Kedua analisis menunjukkan kesimpulan yang sama: Halaman yang dioptimalkan LLM dikutip jika berisi informasi unik dan berguna yang tidak ada di tempat lain di situs Anda.
Formatnya tidak masalah.
Kesimpulan Landwehr sangat jelas: “Anda dapat membuat file 12345.txt dan file tersebut akan dikutip jika berisi informasi yang berguna dan unik.”
Halaman tentang yang terstruktur dengan baik akan memberikan hasil yang sama seperti halaman /ai/about. Dokumentasi API dikutip baik di llms.txt atau terkubur di dokumen biasa Anda.
File-file itu sendiri tidak mendapat perlakuan khusus dari sistem AI.
Konten di dalamnya mungkin saja, tetapi hanya jika konten tersebut benar-benar lebih baik daripada yang sudah ada di halaman reguler Anda.
Data SE Ranking mendukung hal ini dalam skala besar. Tidak ada korelasi antara memiliki llms.txt dan mendapatkan lebih banyak kutipan.
Kehadiran file tersebut tidak membuat perbedaan terukur dalam cara sistem AI mereferensikan domain.
Gali lebih dalam: 7 kebenaran nyata tentang mengukur visibilitas AI dan kinerja GEO
Apa yang sebenarnya dikatakan oleh platform Google dan AI
Tidak ada perusahaan AI besar yang mengonfirmasi penggunaan file llms.txt dalam proses perayapan atau kutipan mereka.
Mueller Google melontarkan kritik paling tajam pada bulan April 2025, membandingkan llms.txt dengan tag meta kata kunci yang sudah usang:
- “[As far as I know]tidak ada layanan AI yang mengatakan bahwa mereka menggunakan LLMs.TXT (dan Anda dapat mengetahui saat melihat log server Anda bahwa mereka bahkan tidak memeriksanya).”
Gary Illyes dari Google memperkuat hal ini pada Search Central Deep Dive pada Juli 2025 di Bangkok, dengan secara eksplisit menyatakan bahwa Google “tidak mendukung LLMs.txt dan tidak berencana untuk mendukungnya.”
Dokumentasi Pusat Google Penelusuran juga sama jelasnya:
- “Praktik terbaik untuk SEO tetap relevan untuk fitur AI di Google Penelusuran. Tidak ada persyaratan tambahan untuk muncul di Ikhtisar AI atau Mode AI, atau pengoptimalan khusus lainnya yang diperlukan.”
OpenAI, Anthropic, dan Perplexity semuanya memelihara file llms.txt mereka sendiri untuk dokumentasi API mereka guna memudahkan pengembang memuat ke asisten AI.
Namun tidak ada yang mengumumkan bahwa crawler mereka benar-benar membaca file ini dari situs web lain.
Pesan yang konsisten dari setiap platform utama: praktik penerbitan web standar mendorong visibilitas dalam penelusuran AI.
Tidak ada file khusus, tidak ada markup baru, dan tidak diperlukan versi terpisah.
Artinya bagi tim SEO
Buktinya menunjukkan satu kesimpulan: berhenti membuat konten yang hanya dapat dilihat oleh mesin.
Pertanyaan Mueller mengarah pada isu inti:
- “Mengapa mereka ingin melihat halaman yang tidak dilihat pengguna?”
Jika perusahaan AI memerlukan format khusus untuk menghasilkan respons yang lebih baik, mereka akan memberi tahu Anda. Seperti yang dia catat:
- “Perusahaan AI tidak dikenal pemalu.”
Data membuktikan bahwa dia benar.
Dari hampir 18.000 kutipan Landwehr, format yang dioptimalkan LLM tidak menunjukkan keuntungan kecuali format tersebut berisi informasi unik yang tidak ada di tempat lain di situs ini.
Analisis SE Ranking terhadap 300.000 domain menemukan bahwa llms.txt justru menambah kebingungan pada model prediksi kutipan mereka daripada memperbaikinya.
Daripada membuat versi bayangan dari konten Anda, fokuslah pada apa yang benar-benar berhasil.
Buat HTML bersih yang dapat diurai dengan mudah oleh manusia dan AI.
Kurangi ketergantungan JavaScript untuk konten penting, yang diidentifikasi oleh Mueller sebagai hambatan teknis sebenarnya:
- “Tidak termasuk JS, yang tampaknya masih sulit untuk banyak sistem ini.”
Render sisi klien yang berat menimbulkan masalah nyata pada penguraian AI.
Gunakan data terstruktur ketika platform telah mempublikasikan spesifikasi resmi, seperti feed produk e-commerce OpenAI.
Tingkatkan arsitektur informasi Anda sehingga konten utama dapat ditemukan dan terorganisir dengan baik.
Halaman terbaik untuk kutipan AI adalah halaman yang sama yang berfungsi untuk pengguna: terstruktur dengan baik, ditulis dengan jelas, dan masuk akal secara teknis.
Hingga perusahaan AI menerbitkan persyaratan formal yang menyatakan sebaliknya, di situlah energi pengoptimalan Anda berada.
Gali lebih dalam: Mitos GEO: Artikel ini mungkin mengandung kebohongan


