")
Kembali ke semua wawasan
Hambatan teknis yang memecahkan AI pada skala (dan cara memperbaikinya)

Amir Ouki
Direktur Pelaksana,
AI & Teknologi Terapan
Jika pilot Anda dioptimalkan untuk kotak pasir dengan data bersih, input statis, dan parameter tetap, kemungkinan tidak siap untuk diproduksi.
Pilot AI sering dirancang untuk membuktikan bahwa sesuatu dapat berhasil. Tetapi ketika saatnya untuk beralih dari alur kerja tunggal ke lingkungan produksi, prototipe awal mulai rusak:
- Infrastruktur tidak dapat mengimbangi
- Jalur pipa data tidak memenuhi tuntutan model
- Logika pelatihan ulang tidak ditentukan atau manual
- Pemantauan tidak ada.
Apa yang dulunya merupakan demo yang menjanjikan sekarang perlu beroperasi di bawah bobot lalu lintas hidup, data real-time, persyaratan tata kelola, dan handoff lintas tim. Inilah yang terlihat seperti hutang teknis ketika AI belum dirancang untuk skala.
Jadi, apa hambatan teknis khas yang akan merusak produk AI pada skala?
Menyelam lebih dalam dengan webinar kami di “Scaling AI dari POC ke Produk Bisnis-Critical”
1. Kendala Konteks-Window
Mengenali dan mengatasi batasan token
Model fondasi menegakkan “jendela konteks” yang tetap, membatasi berapa banyak token yang dapat Anda proses sekaligus. Setelah melebihi itu, Anda akan melihat akurasi diam-diam turun atau kegagalan langsung, terutama dengan input bentuk panjang atau petunjuk rantai.
Cara memperbaikinya
Merencanakan batasan token sebelum jaminan peluncuran Anda tidak akan menemukan langit-langit “tersembunyi” di bawah beban pengguna nyata. Beberapa commons paling banyak berurusan dengan kendala konteks-window meliputi:
-
Generasi Pengambilan-Agung (RAG). Pada inferensi, ambil hanya bagian yang paling relevan daripada melewati seluruh dokumen.
-
Jendela chunking & geser. Pecahkan input ke dalam segmen yang tumpang tindih sehingga setiap permintaan tetap dalam batas token.
-
Varian model konteks panjang. Eksperimen dengan model open-source atau komersial yang dibangun untuk panjang konteks yang diperluas.
2. Latensi real-time
Merancang untuk inferensi sub-detik pada skala
Sebagian besar model besar tidak direkayasa untuk latensi yang sangat rendah. Dalam alur kerja langsung yang menghadap pengguna, bahkan penundaan setengah detik dapat memecahkan SLA.
Cara memperbaikinya
Menyematkan optimisasi ini selama pengembangan dapat membantu Anda mencapai tujuan tanpa mengorbankan kedalaman wawasan secara besar -besaran:
-
Distilasi model & tulang punggung yang lebih ringan. Gunakan varian suling atau kompak untuk jalur waktu-nyata, memesan model lengkap untuk analitik batch.
-
Pra-Komputasi & Caching. Embedding pra-generat atau output parsial umum dan cache untuk pengambilan instan.
-
Aliran prompt yang dioptimalkan & panggilan paralel. Struktur meminta untuk meminimalkan langkah -langkah pembuatan, dan memparalelkan pengambilan plus respons jika memungkinkan.
3. Data Drift & Retraining
Membangun ketahanan untuk data dan konsep penyimpangan
Bahkan model terbaik akan menurun dari waktu ke waktu sebagai distribusi input dan pergeseran perilaku pengguna. Pelatihan ulang manual atau ad-hoc tidak bisa mengimbangi; Perlindungan untuk keduanya harus ada sejak awal.
Cara memperbaikinya
Termasuk pelatihan ulang berbasis kondisi ke dalam alur kerja CI/CD Anda membuat kinerja dapat diandalkan (dan dapat diaudit) tanpa intervensi manusia yang konstan. Prinsip -prinsip utama perencanaan untuk penyimpangan data adalah:
-
Deteksi Drift Otomatis. Terus memantau input dan metrik output utama, dengan peringatan saat ambang batas dilewati.
-
Pelatihan ulang yang dijadwalkan & digerakkan oleh acara. Tentukan aturan yang jelas: berbasis waktu, berbasis kinerja, atau berbasis drift, yang akan memicu jaringan pipa pelatihan ulang secara otomatis.
-
Kerangka kerja pengujian regresi. Pertahankan berkembang tes kereta api Membagi dan menjalankan tes contra-grresi setiap kali skema data atau versi model berubah.
4. Versi sprawl & penelusuran
Memastikan tata kelola melalui versi model dan garis keturunan
Mudah untuk model dan skrip garpu untuk setiap kasus penggunaan, sampai Anda dibiarkan dengan lusinan versi yang tidak dilacak dan tidak ada kepemilikan yang jelas. Praktik -praktik ini bukan hanya kebersihan; Mereka membentuk fondasi AI yang dipercaya, kelas perusahaan.
Cara memperbaikinya
-
Pendaftaran model terpusat. Rekam metadata untuk setiap build: versi, snapshot data pelatihan, hiper-parameter, dan garis keturunan.
-
Versi Input-Output. Masuklah setiap permintaan inferensi dengan versi model yang tepat, batch data, dan output, yang semuanya sangat penting untuk debugging dan kepatuhan.
-
Dasbor Tata Kelola. Kepemilikan komponen permukaan, jalur rollback, dan opsi redeploy satu klik.
Menyelam lebih dalam ke hambatan organisasi yang mencegah penskalaan
Jangan biarkan hutang teknis membunuh solusi yang menjanjikan
Kemacetan teknis tidak terlihat di lab tetapi mencolok dalam produksi. Untuk membuktikan AI Anda yang akan datang ke masa depan:
-
Mengantisipasi batasan token dengan model chunking, rag, atau konteks panjang
-
Optimalkan untuk latensi sub-detik melalui distilasi dan caching
-
Mengotomatiskan tes deteksi, pelatihan ulang, dan regresi drift
-
Menegakkan Keterlacakan dengan Pendaftar, Log, dan Tata Kelola
Di perusahaan AI, model berkinerja terbaik bukanlah yang demo dengan baik. Ini adalah orang yang andal memberikan nilai pada skala.
Solusi AI Dibangun untuk Dampak Komersial
Dari orkestrasi multi-agen hingga lingkungan simulasi untuk pengambilan keputusan, kami merancang dan membangun solusi AI melalui tahap yang jelas dan dapat ditindaklanjuti.
Temukan AI Builds
Ingin membangun solusi AI yang memberikan nilai bisnis nyata pada skala? Mari kita bicara.

Amir Ouki
Direktur Pelaksana, AI & Teknologi Terapan
Amir memimpin tim global BOI tentang ahli strategi produk, desainer, dan insinyur dalam merancang dan membangun teknologi AI yang mengubah peran, fungsi, dan bisnis. Amir suka memecahkan tantangan dunia nyata yang kompleks yang memiliki dampak langsung, dan terutama berfokus pada perangkat lunak yang dipimpin KPI yang mendorong pertumbuhan dan inovasi di atas dan bawah. Dia sering dapat ditemukan (secara objektif) mengevaluasi dan menilai teknologi baru yang dapat bermanfaat bagi klien kami dan telah meluncurkan produk dengan antropik, Apple, Netflix, Palantir, Google, Twitch, Bank of America, dan lainnya.
Terus belajar
Lebih Banyak Sumber Daya di AI Build

Webinar
Menskalakan AI dari POC ke produk yang sangat penting

Webinar
Cara Merancang dan Membangun Solusi AI
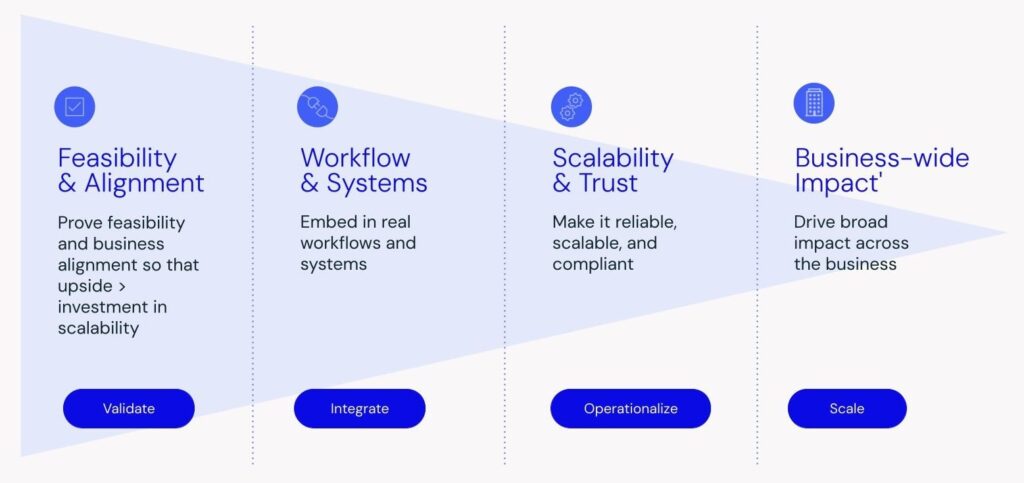
Blog
Apa yang sebenarnya dibutuhkan AI penskalaan: 4 tahap
KTT terbesar di dunia untuk inovator AI kembali pada bulan Desember
Tiket tersedia sekarang

Posting hambatan teknis yang memecahkan AI pada skala (dan cara memperbaikinya) muncul pertama kali di BOI (Dewan Inovasi).


